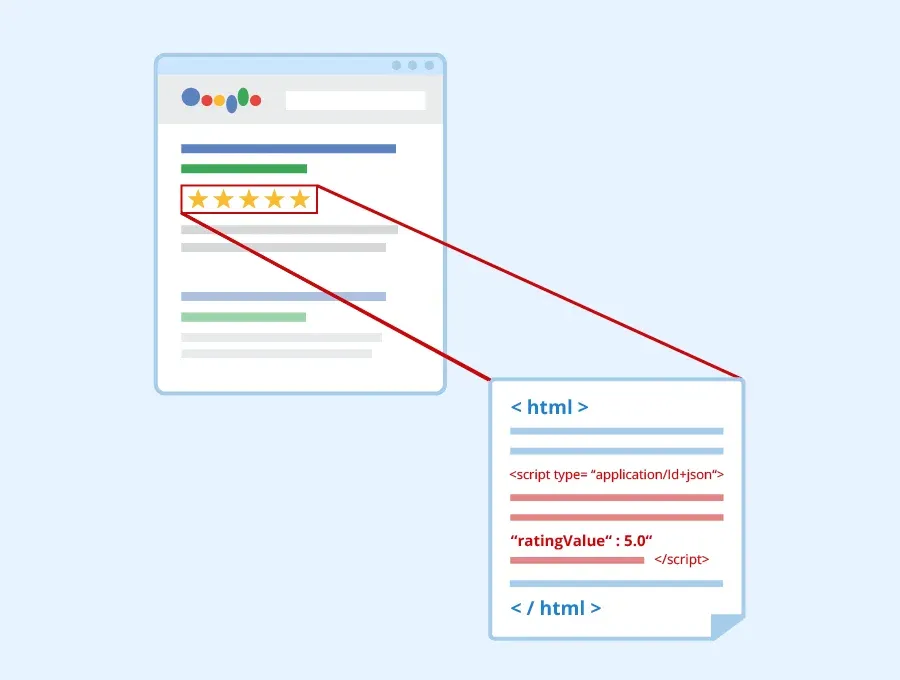
Um vocabulário padronizado de dados estruturados inserido no HTML de uma página para ajudar os mecanismos de busca a compreender o conteúdo com mais precisão. Enquanto dados estruturados é o conceito amplo — qualquer informação organizada em um formato interpretável por máquinas —, schema markup é a implementação prática desse conceito: o conjunto específico de tipos, propriedades e valores que se utiliza para sinalizar ao buscador o que aquele conteúdo realmente representa.
Se você já se perguntou por que alguns resultados no Google aparecem com estrelas de avaliação, perguntas expandidas ou informações de preço diretamente na SERP, a resposta está nos dados estruturados.
O schema markup é a técnica que torna isso possível — e, para profissionais de marketing e desenvolvedores que querem extrair o máximo de visibilidade orgânica, entender como ele funciona não é opcional. É estratégico.
O vocabulário que torna tudo isso possível foi criado e é mantido pelo Schema.org, uma iniciativa colaborativa fundada em 2011 por Google, Bing, Yahoo e Yandex.
O objetivo foi ao mesmo tempo simples e ambicioso: estabelecer uma linguagem comum que permitisse a qualquer site comunicar o significado do seu conteúdo de forma inequívoca para os buscadores — independente da plataforma, do idioma ou da estrutura técnica do projeto.
Na prática, é esse vocabulário compartilhado que garante que um tipo como Product signifique exatamente a mesma coisa para o Google, o Bing e o Yandex.
Como o schema markup funciona na prática
Quando um crawler do Google visita uma página, ele lê o HTML e tenta inferir o significado daquele conteúdo.
Sem dados estruturados, esse processo depende de heurísticas: o algoritmo analisa palavras-chave, contexto semântico e sinais de relevância para deduzir do que se trata a página. É um processo razoavelmente eficiente, mas sujeito a interpretações incorretas.
Com o schema markup, a ambiguidade desaparece. Ao marcar um bloco de conteúdo com o tipo Product e preencher propriedades como name, price e availability, você está dizendo ao Google, de forma explícita: "isso aqui é um produto, ele custa R$ 299 e está em estoque". Não há margem para interpretação equivocada.
Esse entendimento mais preciso tem duas consequências diretas. A primeira é a elegibilidade para rich results. A segunda é uma contribuição ao Knowledge Graph do Google, que utiliza dados estruturados para construir e conectar entidades no seu modelo de compreensão do mundo.
É importante calibrar as expectativas: schema markup não é um fator de ranqueamento direto e confirmado. O que ele faz é aumentar a probabilidade de exibição de rich results, o que, por sua vez, pode elevar a taxa de cliques (CTR) organicamente — e isso, sim, tem impacto indireto na performance de SEO.
Tipos de schema mais utilizados
O Schema.org cataloga centenas de tipos de dados estruturados, mas na prática cotidiana de marketing e desenvolvimento, um conjunto mais enxuto concentra a maior parte das aplicações relevantes. Conhecer os principais tipos — e entender quando cada um se aplica — é o ponto de partida para uma estratégia de dados estruturados eficiente.
Schema de artigo
O tipo Article — e seus subtipos, como NewsArticle e BlogPosting — é utilizado em páginas de conteúdo editorial: posts de blog, artigos de notícias, análises e conteúdos de formato longo em geral. Ele comunica ao Google informações como o título do artigo, o autor, as datas de publicação e de atualização, a imagem principal e a organização responsável pela publicação.
Do ponto de vista prático, esse schema é especialmente relevante para sites que publicam conteúdo com frequência e querem ser elegíveis para recursos como o carrossel de notícias do Google ou a exibição destacada no Google Discover.
A propriedade dateModified, em particular, envia um sinal de atualização de conteúdo que contribui para a indexação mais ágil de novas versões de um artigo — detalhe valioso para equipes de conteúdo que fazem revisões periódicas em posts estratégicos.
Schema de produto
Para e-commerces e páginas de produto, o tipo Product é um dos mais estratégicos de toda a especificação do Schema.org. Ele permite comunicar ao Google atributos como nome, descrição, marca, SKU, preço, moeda, disponibilidade em estoque e condição do produto (novo, recondicionado, usado).
Quando implementado corretamente, o schema de produto habilita a exibição de rich results com informações de preço e disponibilidade diretamente na SERP — uma vantagem competitiva concreta em termos de visibilidade. Um resultado que mostra "R$ 349 — Em estoque" ao lado do título já comunica valor antes mesmo de o usuário clicar. Em mercados com alta concorrência orgânica, esse diferencial visual pode ser decisivo para a taxa de cliques.
Schema de FAQ
O tipo FAQPage é utilizado em páginas que contêm uma lista de perguntas e respostas sobre um determinado tema. Quando implementado corretamente, permite que o Google exiba essas perguntas de forma expandida diretamente no resultado de busca, sem que o usuário precise acessar a página.
Isso gera um efeito de ocupação de espaço na SERP que aumenta a visibilidade e a autoridade percebida. É uma das aplicações mais visíveis de dados estruturados para equipes que trabalham com conteúdo de suporte, central de ajuda ou blogs que respondem dúvidas frequentes do público.
Vale atentar a uma limitação relevante: o Google restringiu progressivamente o uso de FAQPage ao longo de 2023 e 2024, reduzindo a exibição desse rich result em diversas consultas e limitando-o a sites considerados mais autoritativos. A implementação ainda é válida, mas os resultados variam conforme o nicho e a reputação do domínio.
Schema de avaliação
O tipo Review e a propriedade AggregateRating são responsáveis pelas famosas estrelas que aparecem nos resultados de busca. O AggregateRating consolida a nota média de um item — produto, serviço, receita, curso — a partir de múltiplas avaliações, enquanto o Review representa uma avaliação individual com texto e autor.
Um alerta necessário: o Google penaliza o uso manipulado de avaliações em dados estruturados. Markup que exibe notas infladas ou que não corresponde a avaliações reais visíveis na página pode resultar na remoção do rich result ou, em casos mais graves, em ações manuais sobre o domínio.
Schema markup e rich snippets: qual a relação?
Exemplo de rich snippet de avaliações no Google — Foto: Seobility
É comum que os termos "schema markup" e "rich snippets" sejam usados de forma intercambiável, mas eles descrevem coisas diferentes — e entender essa distinção evita confusão na hora de planejar e reportar resultados.
O schema markup é o código: a estrutura de dados inserida no HTML da página. O rich snippet — ou rich result, como o Google passou a denominar oficialmente — é o efeito visual que pode aparecer na SERP como consequência dessa marcação. Em outros termos: o schema é a causa, e o rich result é o potencial resultado.
A palavra "potencial" é deliberada. Ter schema markup implementado corretamente não garante que o Google exibirá um rich result. O buscador reserva para si a decisão final sobre quando e como apresentar esses enriquecimentos. A qualidade geral da página, a autoridade do domínio e a relevância para a consulta específica influenciam essa decisão.
Além dos rich snippets clássicos, os dados estruturados também alimentam outros recursos da SERP, como painéis de conhecimento (Knowledge Panels), carrosséis de resultados para receitas e filmes, e resultados enriquecidos em featured snippets. A tabela abaixo sintetiza os principais tipos de rich results e os schemas que os habilitam:
Rich result
Schema necessário
Benefício principal
Estrelas de avaliação
AggregateRating / Review
Aumento de CTR
FAQ expandido
FAQPage
Maior ocupação de espaço na SERP
Informações de produto
Product
Exibição de preço e disponibilidade
Carrossel de artigos
Article / NewsArticle
Destaque no Google Discover e News
Breadcrumb
BreadcrumbList
Clareza de hierarquia na SERP
Resultados de evento
Event
Data, local e link de ingresso em destaque
Compreender essa relação de causa e efeito é fundamental para definir prioridades. Não faz sentido implementar dezenas de tipos de schema simultaneamente sem clareza sobre quais rich results são mais relevantes para o modelo de negócio e para o comportamento do público-alvo.
Como implementar schema no seu site
Existem três formatos de implementação de dados estruturados reconhecidos pelo Google: JSON-LD, Microdata e RDFa. Cada um tem características próprias, e a escolha entre eles impacta tanto a facilidade de manutenção quanto a integração com o restante do código da página.
JSON-LD
O JSON-LD (JavaScript Object Notation for Linked Data) é o formato recomendado pelo Google e, na prática, o mais adotado atualmente. Toda a marcação é inserida em um bloco <script type="application/ld+json"> dentro da <head> ou do <body> do HTML — sem nenhuma necessidade de alterar o markup do conteúdo visível.
Essa separação entre dado estruturado e estrutura visual é a principal vantagem do JSON-LD. Desenvolvedores conseguem adicionar, editar e remover schemas sem tocar nos elementos HTML da página, o que reduz o risco de quebras visuais e facilita a manutenção em escala. Veja um exemplo de schema de produto em JSON-LD:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Product",
"name": "Tênis Running Pro X",
"description": "Tênis de corrida com amortecimento responsivo e solado de alta durabilidade.",
"brand": {
"@type": "Brand",
"name": "SportMax"
},
"sku": "TRP-001",
"offers": {
"@type": "Offer",
"priceCurrency": "BRL",
"price": "349.90",
"availability": "https://schema.org/InStock",
"url": "https://www.exemplo.com.br/tenis-running-pro-x"
},
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.7",
"reviewCount": "128"
}
}
</script>
Para a maioria dos projetos — sejam sites institucionais, blogs ou e-commerces — o JSON-LD é a escolha mais segura e escalável. Plataformas como WordPress, Shopify e VTEX disponibilizam plugins e módulos nativos que geram esse formato automaticamente, reduzindo a necessidade de codificação manual e o risco de erros em produção.
Microdata
O Microdata é um formato que insere os atributos de schema diretamente nas tags HTML do conteúdo visível. Em vez de um bloco separado, os dados estruturados são acoplados ao markup da página por meio de atributos como itemscope, itemtype e itemprop.
A principal desvantagem do Microdata é justamente essa dependência do HTML do conteúdo. Qualquer alteração de layout ou refatoração de template pode comprometer a integridade dos dados estruturados, o que eleva o esforço na hora da manutenção. O formato permanece válido e pode ser uma opção em sistemas legados onde injetar blocos de script é mais difícil do que adicionar atributos diretamente ao HTML existente.
RDFa
O RDFa (Resource Description Framework in Attributes) segue uma lógica parecida com a do Microdata: os dados são incorporados ao HTML por meio de atributos específicos, como vocab, typeof e property. A diferença está na origem — o RDFa deriva de um padrão W3C mais abrangente, voltado originalmente para a web semântica e para o conceito de linked data.
Na prática, o RDFa tem uso menos frequente em projetos comerciais e aparece com mais regularidade em publicações acadêmicas, portais governamentais e sistemas que já adotavam padrões de linked data antes da popularização do JSON-LD. Para novos projetos, ele dificilmente será a primeira escolha.
A tabela abaixo compara os três formatos nos critérios mais relevantes para o dia a dia de desenvolvimento e manutenção:
Critério
JSON-LD
Microdata
RDFa
Recomendado pelo Google
Sim
Sim
Sim
Separado do HTML visível
Sim
Não
Não
Facilidade de manutenção
Alta
Média
Média
Suporte nativo em CMS e plataformas
Amplo
Limitado
Limitado
Adoção no mercado
Predominante
Moderada
Baixa
Como validar dados estruturados
Implementar schema markup sem validar é como publicar um formulário sem testar o envio: assume-se que funciona, mas não há confirmação real. A validação é uma etapa obrigatória em qualquer fluxo de implementação responsável — e não uma verificação pontual feita uma única vez.
O Google disponibiliza duas ferramentas principais para essa finalidade. A Rich Results Test é a mais direta: ela analisa uma URL ou um trecho de código e indica quais rich results a página é elegível a exibir, além de listar erros e avisos específicos por tipo de schema. É a ferramenta ideal para verificações rápidas durante o desenvolvimento ou após alterações de template.
O Google Search Console oferece uma perspectiva diferente e complementar. Na seção "Melhorias", ele agrupa os dados estruturados detectados em todo o site, exibe o histórico de erros e permite acompanhar se as correções surtiram efeito ao longo do tempo. Para projetos com grande volume de páginas, essa visão agregada é indispensável para monitoramento contínuo.
Para validação independente do Google, o Schema Markup Validator, mantido pelo próprio Schema.org, verifica se o código está em conformidade com a especificação técnica do vocabulário — sem considerar as regras específicas de rich results do Google. É útil para garantir que o markup está sintaticamente correto antes de testá-lo no contexto da SERP.
Uma boa prática é incluir a validação de schema markup no processo de QA de qualquer deploy que altere templates ou componentes de página. Erros que passam despercebidos em produção podem invalidar rich results que já estavam ativos, gerando quedas de CTR que nem sempre são imediatamente associadas à causa técnica real.
Erros comuns ao usar schema markup
A maioria dos problemas com dados estruturados não vem de falta de conhecimento teórico, mas de descuidos na implementação ou de interpretações equivocadas sobre o que o Google permite e espera. Conhecer os erros mais frequentes ajuda a evitá-los antes que causem impacto mensurável.
O erro mais grave — e o único com potencial de penalidade real — é o markup enganoso: marcar conteúdo que não existe na página ou que não corresponde ao que o usuário vê. Um exemplo recorrente é adicionar AggregateRating com nota 5.0 em uma página que não exibe avaliações reais. O Google interpreta isso como manipulação e pode remover o rich result ou, em casos mais graves, aplicar uma ação manual ao domínio.
A ausência de propriedades obrigatórias também é muito frequente. Cada tipo de schema tem propriedades que o Google considera necessárias para a elegibilidade a rich results. No schema de produto, por exemplo, a ausência de offers — com pelo menos price e priceCurrency — costuma inviabilizar a exibição de preço na SERP. A documentação oficial do Google para cada tipo de rich result especifica exatamente quais propriedades são obrigatórias e quais são apenas recomendadas.
O schema aplicado em páginas inadequadas é outro equívoco recorrente. FAQPage em uma página de categoria de e-commerce, Product em um artigo de blog ou Article em uma landing page sem conteúdo editorial são exemplos de marcação que, no mínimo, não gera benefício — e pode confundir os crawlers sobre a natureza real da página.
Por fim, há o problema da desatualização. Preços, disponibilidade de estoque, datas de eventos e médias de avaliação mudam com frequência. Schema markup que não acompanha essas mudanças em tempo real passa a exibir informações incorretas na SERP, o que prejudica a experiência do usuário e pode levar o Google a desconsiderar o rich result progressivamente.
Conclusão
O schema markup é, na prática, uma forma de tornar o conteúdo de um site mais legível para as máquinas — e, por extensão, mais visível e útil para as pessoas.
Para profissionais de marketing, representa uma alavanca de CTR orgânico que não depende de produzir mais conteúdo, mas de estruturar melhor o que já existe. Para desenvolvedores, é uma camada técnica com impacto direto nos resultados de negócio.
A implementação mais eficiente começa com priorização: quais tipos de schema são mais relevantes para o modelo de negócio, quais rich results têm maior potencial de impacto no público-alvo e quais páginas devem ser trabalhadas primeiro. JSON-LD com validação sistemática via Rich Results Test e Search Console é, em quase todos os cenários, o caminho mais seguro e escalável.
Dados estruturados não são uma solução mágica de SEO — mas são uma das poucas técnicas em que o investimento de implementação tem retorno mensurável, direto e relativamente rápido na performance orgânica. Ignorá-los significa deixar uma vantagem competitiva concreta na mesa.